Turn documents into LLM-ready datasets
FlexOrch extracts structured data from raw documents, scores quality, masks sensitive fields, and builds export-ready datasets — all through one automated pipeline.
For operations, compliance, and AI teams
Unify fragmented document work under one execution model and make data reusable for downstream AI and analytics.
Privacy built in
Masking decisions are made inside the pipeline before any data leaves.
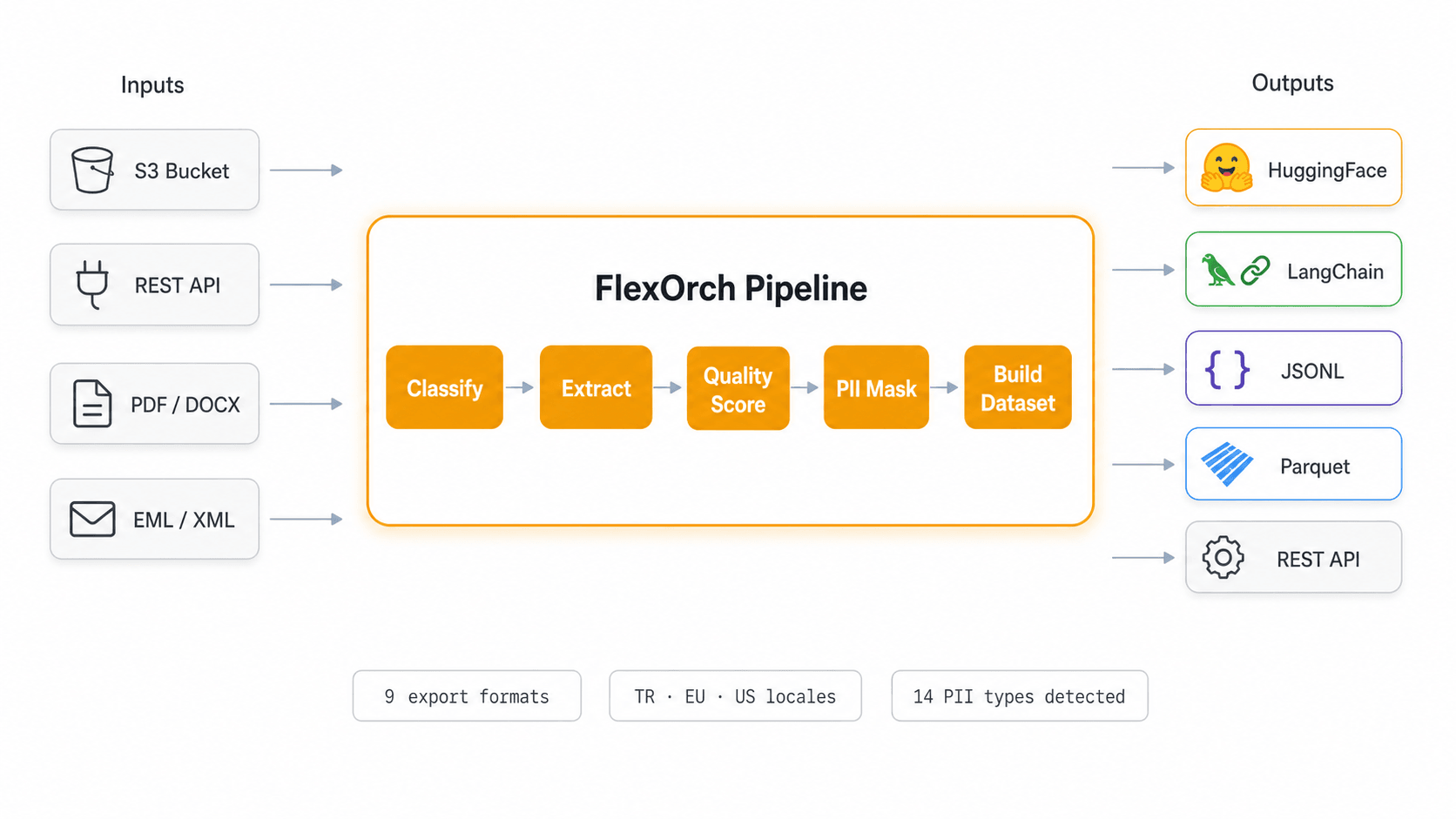
LLM-ready dataset build
Structured output, export formats, and lineage stay in one execution record.
Automatic quality scoring
Every document produces a confidence score, quality grade, and warning signals.
One pipeline from raw documents to trusted datasets
One execution model instead of separate parsers, manual cleanup, and bolted-on privacy checks.
Turn fragmented document work into a platform capability
FlexOrch is built for teams where document understanding, privacy, and dataset readiness must work together — not in separate systems.
Document processing, privacy, and export converge in one product logic.
Replace scattered tooling with a single platform surface, one execution language, and reusable data outputs.
Execution-centered
Every upload, job, execution, and export becomes part of a visible operational record.
Privacy-native
Privacy controls are not an add-on. They are part of the product's core behavior.
LLM-ready output
Structured data, quality signals, and lineage make downstream AI usage easier.
API-first design
Every platform capability is accessible directly via API. The UI is a consumer, not the authority.
Built for platform teams, product teams, and API consumers
A stable resource model, Python and TypeScript SDKs, and a predictable path from file processing to dataset export.
from flexorch_audit import audit, redact_for_llm
text = open("contract.txt").read()
result = audit(text, locale="tr")
result.quality_grade # "A"
result.quality_score # 0.91
result.pii_summary
# [{"type": "national_id_tr", "count": 3},
# {"type": "email", "count": 2}]
clean = redact_for_llm(text, locale="tr")Every platform capability is accessible directly via API. The UI is a consumer, not the authority.
Outputs feed directly into HuggingFace datasets, LangChain, and LlamaIndex pipelines.
Typed fields, quality signals, and export behavior are defined in one place.
30 days free. No credit card required.
Get started now — upload your documents, see the pipeline, export your dataset.